INT8 양자화가 추론 속도를 2배 높이는 구조
Quanto는 PyTorch 모델을 INT8/INT4로 양자화해 메모리를 절반으로 줄이고 추론 속도를 2배까지 높이는 백엔드다. Hugging Face Optimum에 통합되어 있으며, 기존 모델 코드를 바꾸지 않고 양자화를 적용할 수 있다. 이 글은 Quanto의 양자화 방식, 다른 기법과의 차이, 실전 적용 조건을 다룬다.
LLM을 프로덕션에 배포할 때 메모리 병목이 자주 발생한다. 70억 파라미터 모델을 FP16으로 로드하면 약 14GB VRAM이 필요하다. 같은 모델을 INT8로 양자화하면 7GB로 줄어들고, INT4는 3.5GB까지 내려간다. Quanto는 이 변환을 PyTorch 네이티브 연산으로 처리해 별도 커널 없이 CPU/GPU에서 작동한다.
양자화가 메모리를 절반으로 줄이는 원리
양자화(Quantization)는 FP32나 FP16 가중치를 INT8/INT4 정수로 변환하는 기법이다. 각 가중치 값을 정수 범위로 매핑하고, 추론 시 역변환해 연산한다. 이 과정에서 정밀도가 약간 손실되지만, 대부분의 LLM은 1~2% 정확도 하락으로 메모리를 절반 이상 줄일 수 있다.
Quanto는 두 가지 방식을 지원한다.
선형 양자화(Linear Quantization): 가중치의 최솟값과 최댓값을 INT8 범위(-128~127)로 선형 매핑한다. 계산이 단순해 CPU에서도 빠르다.
아핀 양자화(Affine Quantization): 스케일 팩터와 제로 포인트를 사용해 비대칭 분포를 더 정밀하게 표현한다. 이상치가 많은 레이어에서 정확도 손실을 줄인다.
from optimum.quanto import quantize, freeze
import torch
model = torch.hub.load('pytorch/vision', 'resnet50', pretrained=True)
# INT8 양자화 적용
quantize(model, weights=torch.int8, activations=torch.int8)
freeze(model)
# 추론
output = model(input_tensor)
quantize() 함수는 모델의 가중치를 INT8로 변환하고, freeze()는 양자화된 상태를 고정한다. 이후 추론 시 자동으로 INT8 연산이 적용된다.
다른 양자화 기법과의 구조적 차이
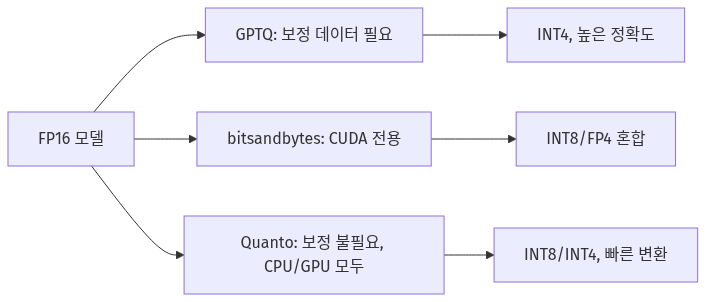
GPTQ와 bitsandbytes는 널리 쓰이는 양자화 라이브러리지만, Quanto와는 설계 철학이 다릅니다.
- GPTQ: 레이어별로 가중치를 재보정(Calibration)해 INT4 양자화 시에도 정확도 손실을 최소화합니다. 하지만 보정 과정에 샘플 데이터가 필요하고, 변환 시간이 깁니다. 70억 파라미터 모델을 기준으로 GPU에 따라 몇 분에서 몇십 분이 걸릴 수 있습니다.
- bitsandbytes: INT8/FP4 혼합 정밀도를 지원하며, 특정 레이어만 양자화할 수 있습니다. CUDA 전용 커널로 구현되어 GPU에서는 빠르지만 CPU 추론은 지원하지 않습니다.
- Quanto: 보정 데이터 없이 바로 양자화가 가능하고, PyTorch 표준 연산만 사용해 CPU/GPU/MPS 모두 작동합니다. 정확도는 GPTQ보다 약간 낮을 수 있지만, 변환 속도가 빠르고 디버깅이 쉽습니다. 프로토타입 단계나 CPU 배포 환경에서 선택지가 됩니다.
활성화 양자화가 속도에 미치는 영향
Quanto는 가중치뿐 아니라 활성화(Activation)도 양자화할 수 있다. 활성화 양자화는 레이어 출력 값을 INT8로 변환해 다음 레이어 입력으로 넘긴다. 이 방식은 메모리 대역폭을 줄여 큰 배치 크기나 긴 시퀀스 처리 시 속도를 높인다.
하지만 활성화는 입력마다 분포가 바뀌기 때문에 가중치보다 양자화 오차가 크다. 특히 Transformer의 Self-Attention 출력처럼 이상치가 많은 레이어에서 정확도가 떨어질 수 있다. 실험에 따라 활성화 양자화를 켜면 추론 속도가 20~40% 빨라지는 반면, MMLU 같은 벤치마크 점수는 1~3%p 하락하는 경우도 있다.
활성화 양자화는 정확도보다 처리량이 중요한 배치 추론 작업(문서 분류, 로그 분석)에서 효과가 있다. 반대로 생성 품질이 민감한 작업(요약, 번역)에서는 가중치만 양자화하는 것이 안전하다.
Quanto를 써야 하는 상황과 대안
Quanto는 다음 조건에서 적합하다.
빠른 프로토타입: 보정 데이터 준비 없이 기존 모델에 양자화를 바로 적용해 메모리 사용량을 확인할 수 있다. RAG 파이프라인을 로컬에서 테스트할 때 70억 파라미터 모델을 INT8로 변환하면 16GB RAM 노트북에서 돌아간다.
CPU 추론 환경: GPU 없는 서버나 엣지 디바이스에서 모델을 배포할 때 bitsandbytes는 쓸 수 없다. Quanto는 PyTorch CPU 백엔드로 작동하므로 x86/ARM 서버 모두 지원한다.
디버깅이 중요한 단계: Quanto는 커스텀 CUDA 커널 없이 순수 PyTorch 연산으로 구현되어 있어, 양자화 레이어를 단계별로 추적하고 가중치를 직접 검증할 수 있다.
반면 프로덕션 배포에서 정확도가 최우선이고 GPU가 확보된 상황이라면 GPTQ가 더 나은 선택이다. GPTQ는 보정 시간이 걸리지만 INT4 양자화에서도 정확도 손실이 1% 미만으로 유지된다. bitsandbytes는 LoRA 파인튜닝과 양자화를 동시에 적용할 때 효율적이다.
Quanto는 모든 상황의 최적해는 아니지만, 양자화 실험을 빠르게 시작하거나 CPU 환경에 배포해야 할 때 장벽이 낮다. 정확도와 속도 간 트레이드오프를 직접 측정한 뒤 프로덕션용 양자화 기법을 결정하는 것이 현실적이다.
실전 적용 시 확인할 설정
Quanto를 실전에 쓸 때 아래 항목을 점검한다.
양자화 범위: 전체 모델을 양자화할지, 특정 레이어만 할지 정한다. Transformer의 Embedding과 LM Head는 양자화하지 않는 게 정확도에 유리하다.
from optimum.quanto import quantize, freeze
# Embedding과 LM Head 제외
quantize(
model,
weights=torch.int8,
exclude=["model.embed_tokens", "lm_head"]
)
freeze(model)
배치 크기: INT8 양자화는 배치 크기가 클수록 처리량 이득이 크다. 단일 샘플 추론에서는 FP16 대비 속도 향상이 크지 않을 수 있지만, 배치 크기 32 이상에서는 GPU 아키텍처에 따라 최대 2배까지 빨라질 수 있다.
정확도 검증: 양자화 후 반드시 평가 데이터셋으로 정확도를 측정한다. MMLU, HumanEval 같은 벤치마크 점수가 2% 이상 떨어지면 양자화 방식을 조정하거나 혼합 정밀도를 고려한다.
양자화 파이프라인 선택 기준
모델 최적화가 필요한 시점에 Quanto를 먼저 시도하고, 정확도나 속도가 부족하면 GPTQ로 넘어가는 순서가 효율적이다. CPU 배포 환경이라면 Quanto가 유일한 선택지가 될 수 있다. 클라우드 GPU에서 대규모 배치 추론을 돌릴 때는 bitsandbytes의 혼합 정밀도가 처리량을 높인다.
양자화는 메모리 제약을 푸는 도구지만, 정확도 손실을 항상 동반한다. 프로덕션에 투입하기 전에 실제 작업 데이터로 품질을 검증하는 단계를 생략하면 안 된다.
더 읽을 자료
- [참고] Hugging Face 블로그: Quanto 공식 소개 (https://huggingface.co/blog/quanto-introduction)
- [참고] Optimum Quanto GitHub (https://github.com/huggingface/optimum-quanto)