LLM 파인튜닝, Unsloth로 2배 빠르게
Unsloth를 사용하면 LLM 파인튜닝 속도를 최대 2배 높이고 메모리 사용량은 50%까지 줄일 수 있습니다. 코드 변경은 단 두 줄로 충분합니다. 이 라이브러리는 Hugging Face TRL(Transformer Reinforcement Learning)과 완벽하게 호환됩니다. 파인튜닝 과정의 가장 큰 병목인 QLoRA 역전파(backpropagation) 연산을 Triton 언어로 직접 구현해 최적화한 덕분입니다.
LLM 파인튜닝은 많은 시간과 고사양 GPU 자원을 요구합니다. QLoRA는 4비트 양자화를 통해 메모리 사용량을 줄여 이 문제를 일부 해결했지만, 학습 속도까지 개선하지는 못했습니다. 특히 역전파 과정에서 성능 저하가 발생합니다. Unsloth는 이 특정 구간의 연산을 수동으로 최적화하여 전체 파인튜닝 파이프라인의 효율을 극대화합니다.
QLoRA 역전파의 병목 현상
QLoRA(Quantized Low-Rank Adaptation)는 4비트 양자화와 LoRA를 결합해 LLM 파인튜닝에 필요한 메모리를 줄이는 기법입니다. 모델의 가중치를 4비트로 양자화해 저장하고, 순전파(forward pass) 시에는 이를 16비트(bfloat16)로 동적 변환하여 연산합니다. 이 과정 덕분에 VRAM이 24GB인 GPU에서도 70B 모델 파인튜닝이 가능합니다.
문제는 역전파 과정에서 발생합니다. 순전파와 달리 역전파 시에는 bitsandbytes 라이브러리의 구현이 최적화되어 있지 않습니다. 기울기(gradient) 계산을 위해 4비트 가중치를 다시 16비트로 변환하는 과정이 순수 파이썬 코드로 구현되어 GPU 연산의 효율을 온전히 활용하지 못합니다. 이 부분이 전체 학습 속도를 저하시키는 주된 병목 지점입니다.
Unsloth의 수동 최적화 커널
Unsloth는 이 병목을 해결하기 위해 Triton을 도입합니다. Triton은 OpenAI에서 개발한 파이썬 기반 언어로, CUDA 코드를 직접 작성하는 것보다 쉽게 고성능 GPU 커널을 작성할 수 있게 해줍니다. Unsloth 개발팀은 Triton을 사용해 QLoRA 역전파 과정을 위한 커널을 수동으로 재작성했습니다.
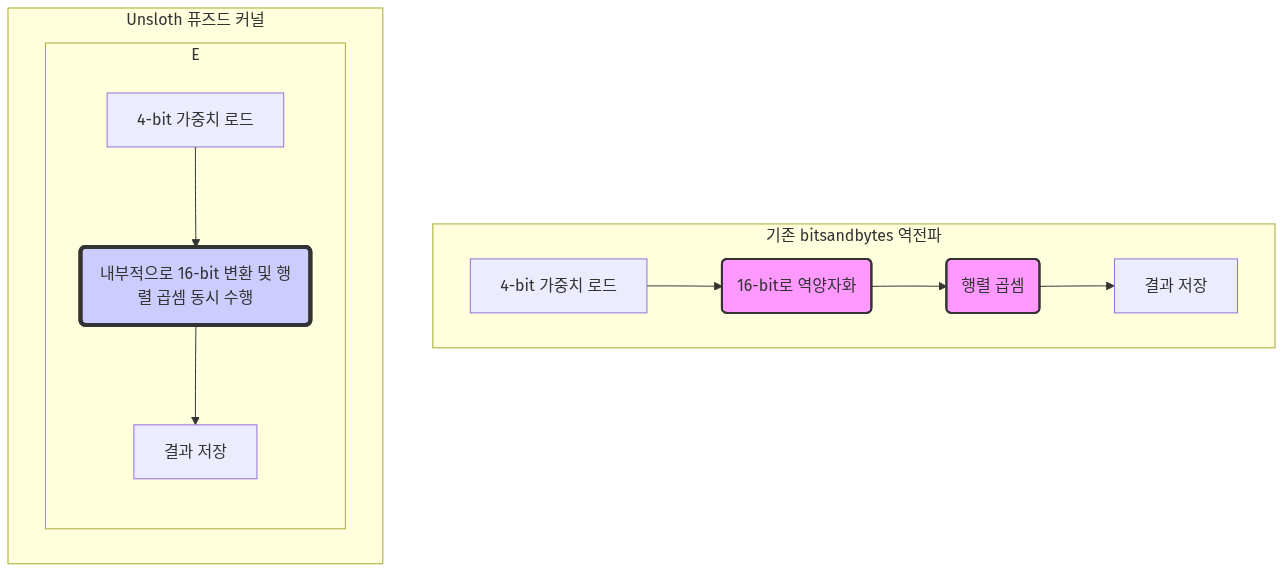
Unsloth의 커널은 여러 연산을 하나로 묶는 퓨즈드 커널 (fused kernel) 기법을 사용합니다. 기존 bitsandbytes가 가중치 역양자화 → 행렬 곱셈 연산을 별도 단계로 처리했다면, Unsloth는 이 두 과정을 하나의 커널 안에서 실행합니다. 이를 통해 GPU 메모리와 연산 유닛 간 데이터 이동을 최소화하고, 전체 연산 속도를 높입니다.
Unsloth는 QLoRA 역전파뿐만 아니라 RoPE(Rotary Positional Embedding) 연산과 cross-entropy loss 계산 과정도 최적화합니다. 모델의 attention layer 내부 연산까지 직접 수정하여 추가적인 속도 향상을 이끌어냅니다.
벤치마크: 속도 및 메모리 사용량 비교
벤치마크 결과는 Unsloth의 효과를 명확히 보여줍니다. 모든 테스트는 TRL 라이브러리를 기반으로, Unsloth를 적용한 경우와 적용하지 않은 경우를 비교했습니다.
아래 표는 NVIDIA A100 GPU에서 Llama 2 7B 모델을 파인튜닝한 결과입니다. Unsloth는 bitsandbytes를 사용한 일반적인 TRL 파인튜닝 대비 2.19배, Hugging Face의 최신 구현 대비 1.95배 빠른 속도를 기록했습니다.
| 라이브러리 | 훈련 시간 (초) | 속도 향상 |
|---|---|---|
TRL (bitsandbytes) | 10076 | 1x |
TRL (torch.compile) | 9534 | 1.06x |
| TRL + Unsloth | 4593 | 2.19x |
표 1: NVIDIA A100 (40GB) GPU, Llama 2 7B 모델 파인튜닝 속도 비교. 수치는 alpaca-ko 데이터셋 52,000개 샘플 1 epoch 기준.
메모리 사용량 감소 효과도 큽니다. RTX 4090 GPU에서 Mistral 7B 모델을 파인튜닝할 때, Unsloth는 최대 50%의 메모리 사용량 감소를 보였습니다. 이는 더 큰 배치 사이즈를 사용하거나, 더 큰 모델을 제한된 VRAM 환경에서 학습시킬 수 있음을 의미합니다.
| 라이브러리 | 최대 VRAM 사용량 (GB) | 메모리 절감 |
|---|---|---|
TRL (bitsandbytes) | 15.36 | 1x |
| TRL + Unsloth | 7.64 | 50.3% |
표 2: NVIDIA RTX 4090 (24GB) GPU, Mistral 7B 모델 파인튜닝 메모리 사용량 비교.
Unsloth와 TRL을 사용한 파인튜닝 코드
Unsloth를 기존 파인튜닝 코드에 적용하는 방법은 간단합니다. 모델을 로드하고 PEFT(Parameter-Efficient Fine-Tuning) 설정을 적용하는 부분에서 두 줄만 수정하면 됩니다.
먼저 필요한 라이브러리를 설치합니다.
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps trl peft accelerate bitsandbytes
아래는 Mistral 7B 모델을 파인튜닝하는 예시 코드입니다. FastLanguageModel 클래스를 사용하는 것이 핵심입니다.
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
from unsloth import FastLanguageModel # 1. Unsloth 클래스 임포트
# 모델과 토크나이저 로드
model_name = "unsloth/mistral-7b-bnb-4bit"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=2048,
dtype=None,
load_in_4bit=True,
)
# 2. PEFT 모델로 변환
# Unsloth는 모델의 attention layer 등을 내부적으로 수정한다.
model = FastLanguageModel.get_peft_model(
model,
r=16,
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing=True,
random_state=42,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
)
# 데이터셋 로드
dataset = load_dataset("imdb", split="train")
# SFTTrainer 설정
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=2048,
tokenizer=tokenizer,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=10,
max_steps=60,
learning_rate=2e-4,
fp16=not torch.cuda.is_bf16_supported(),
bf16=torch.cuda.is_bf16_supported(),
logging_steps=1,
output_dir="outputs",
optim="adamw_8bit",
seed=42,
),
)
# 훈련 시작
trainer.train()
FastLanguageModel.from_pretrained 함수는 모델 로딩 시 Unsloth의 최적화 커널을 적용할 준비를 합니다. 이후 FastLanguageModel.get_peft_model을 호출하면 모델의 특정 레이어(예: attention)가 Unsloth의 고속화된 버전으로 교체됩니다. 이 두 단계만으로 기존 TRL 워크플로에 속도와 메모리 최적화를 적용할 수 있습니다.
트레이드오프와 고려사항
Unsloth의 장점은 명확합니다. 파인튜닝 속도 향상과 메모리 절감입니다. 모델의 최종 성능이나 정확도 저하는 보고된 바 없습니다. 이는 같은 시간과 비용으로 더 많은 실험을 하거나 더 큰 모델을 다룰 수 있다는 의미입니다.
그러나 이 접근법에는 트레이드오프가 존재합니다. 가장 큰 제약은 호환성입니다. Unsloth는 특정 모델 아키텍처의 연산 커널을 직접 수정하기 때문에 모든 LLM을 지원하지는 않습니다. 현재 Llama, Mistral, Yi, Qwen, Gemma 등 널리 사용되는 모델 계열을 중심으로 지원이 확장되고 있습니다. 사용하려는 모델이 지원 목록에 있는지 먼저 확인해야 합니다. 또한, 새로운 GPU 아키텍처가 등장했을 때 Unsloth가 이를 지원하기까지 시간이 걸릴 수 있습니다.
요약 및 제언
Unsloth는 QLoRA 파인튜닝의 역전파 병목을 Triton 기반의 수동 최적화 커널로 해결합니다. 그 결과 코드 수정을 최소화하면서도 학습 속도를 2배 가까이 높이고 메모리 사용량을 절반으로 줄이는 효과를 제공합니다.
LLM 파인튜닝 속도가 프로젝트의 병목이 되거나, 제한된 GPU 자원으로 더 큰 모델을 학습시켜야 할 때 Unsloth는 유용한 대안이 될 수 있습니다. 다만, 지원하는 모델과 하드웨어 아키텍처에 제약이 있으므로 적용 전 호환성 확인이 필요합니다.